AWSを運用していると、避けて通れないのが「サービスの終了」です。
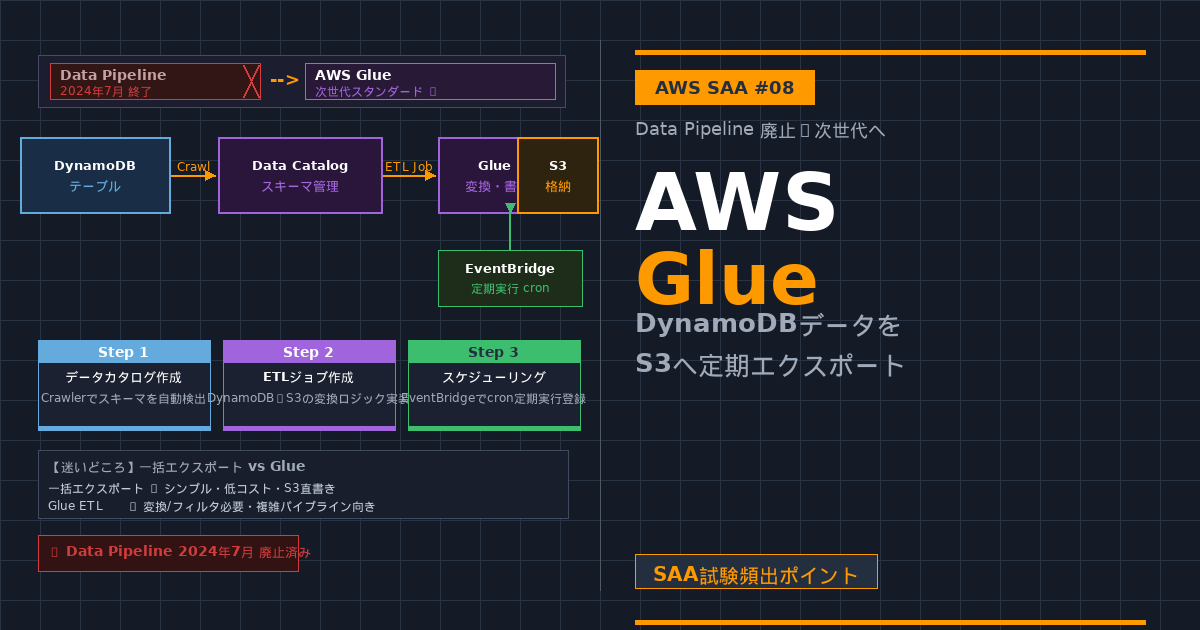
以前はDynamoDBのデータをS3へ定期的に書き出す際、AWS Data Pipelineを使うのが定番でした。しかし、2024年7月にその歴史に幕を閉じます。そこで、次世代のスタンダードとしてSAA試験でも問われるのが、AWS Glueへの移行です。
「今まで動いていたものをどう置き換えるか?」という視点で、最新のデータ移行パイプラインを整理しましょう。
なぜ「Data Pipeline」から「Glue」なのか?
かつてのData Pipelineは「テンプレートを選んで回す」手軽さがありましたが、現在はより強力なAWS Glueがその役割を引き継いでいます。
- サーバーレス
管理の手間が一切不要。 - ETLが得意
抽出(Extract)、変換(Transform)、書き出し(Load)を一貫して行えます。 - スケジュール実行
「毎週月曜日の朝に実行」といった、Data Pipelineでやっていた定期実行もばっちり設定可能です。
AWS Glueで構築する「定期エクスポート」の3ステップ
実際に構成を組む際の流れを、試験に出るポイントに絞って解説します。
ステップ1:データカタログの作成
まず、Glueの「クローラー」を使ってDynamoDBテーブルをスキャンします。これでGlueが「あ、ここにこういうデータがあるんだな」と認識する(メタデータの登録)ことができます。
ステップ2:ETLジョブの作成
次に、メインの処理となる「ジョブ」を作ります。
- ソース(元)
データカタログに登録したDynamoDB - ターゲット(先)
必要に応じて、ここでデータの形式(CSVやparquet)を変換したり、不要な列を削ったりする加工が可能です。
ステップ3:スケジューリング
Glueのトリガー機能を使って、実行サイクル(実行頻度や時間)を設定します。これで、Data Pipelineの時と同じように、決まった時間に自動でデータがS3へ保存されるようになります。
【迷いどころ】一括エクスポート vs Glue
DynamoDBには「Amazon S3への一括エクスポート(Export to S3)」という機能もあります。どちらを選ぶべきかの判断基準はこちら。
| 機能 | 特徴 | 使い時 |
| Export to S3 | 標準機能。設定が非常に楽。 | 「今すぐ一回だけ」バックアップしたい時。 |
| AWS Glue | 高度な加工が可能。 | 「定期的に」スケジュール実行したい時。 |
試験で役立つ!キーワード判別法
データ移行やバッチ処理の問題で、以下の言葉があればAWS Glueが正解の鍵です。
- 「Data Pipelineからの移行先」
- 「定期的なスケジュール(毎週/毎月)」
- 「データの変換や加工を伴うエクスポート」
- 「サーバーレスなETLジョブ」
今回の学び:攻略の格言
「定期エクスポートの看板娘はData PipelineからGlueへ。スケジュールと加工が必要なら、Glue一択!」
あとがき:一歩ずつ、合格へ!
最後まで読んでいただき、ありがとうございました。
サービスが終了すると聞くと少し焦りますが、新しいサービス(Glue)の方がより柔軟で強力な機能を持っています。試験勉強をしていると、こうした「時代の変わり目」に立ち会えるのも面白いですよね。
「今までこうやってたから」に縛られず、常に「今のベストプラクティスは何か?」をアップデートしていく。これこそが、ソリューションアーキテクトに求められる姿勢なのだと実感しました。
それでは、次回の記事でお会いしましょう!


